 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse IFEval: Can LLMs Unlearn Stubborn Training Conventions to Follow Real Instructions?
Sep 04, 2025Large Language Models (LLMs) achieve strong performance on diverse tasks but often exhibit cognitive inertia, struggling to follow instructions that conflict with the standardized patterns learned during supervised fine-tuning (SFT). To evaluate this limitation, we propose Inverse IFEval, a benchmark that measures models Counter-intuitive Abilitytheir capacity to override training-induced biases and comply with adversarial instructions. Inverse IFEval introduces eight types of such challenges, including Question Correction, Intentional Textual Flaws, Code without Comments, and Counterfactual Answering. Using a human-in-the-loop pipeline, we construct a dataset of 1012 high-quality Chinese and English questions across 23 domains, evaluated under an optimized LLM-as-a-Judge framework. Experiments on existing leading LLMs demonstrate the necessity of our proposed Inverse IFEval benchmark. Our findings emphasize that future alignment efforts should not only pursue fluency and factual correctness but also account for adaptability under unconventional contexts. We hope that Inverse IFEval serves as both a diagnostic tool and a foundation for developing methods that mitigate cognitive inertia, reduce overfitting to narrow patterns, and ultimately enhance the instruction-following reliability of LLMs in diverse and unpredictable real-world scenarios.
The Sound of Risk: A Multimodal Physics-Informed Acoustic Model for Forecasting Market Volatility and Enhancing Market Interpretability
Aug 26, 2025



Information asymmetry in financial markets, often amplified by strategically crafted corporate narratives, undermines the effectiveness of conventional textual analysis. We propose a novel multimodal framework for financial risk assessment that integrates textual sentiment with paralinguistic cues derived from executive vocal tract dynamics in earnings calls. Central to this framework is the Physics-Informed Acoustic Model (PIAM), which applies nonlinear acoustics to robustly extract emotional signatures from raw teleconference sound subject to distortions such as signal clipping. Both acoustic and textual emotional states are projected onto an interpretable three-dimensional Affective State Label (ASL) space-Tension, Stability, and Arousal. Using a dataset of 1,795 earnings calls (approximately 1,800 hours), we construct features capturing dynamic shifts in executive affect between scripted presentation and spontaneous Q&A exchanges. Our key finding reveals a pronounced divergence in predictive capacity: while multimodal features do not forecast directional stock returns, they explain up to 43.8% of the out-of-sample variance in 30-day realized volatility. Importantly, volatility predictions are strongly driven by emotional dynamics during executive transitions from scripted to spontaneous speech, particularly reduced textual stability and heightened acoustic instability from CFOs, and significant arousal variability from CEOs. An ablation study confirms that our multimodal approach substantially outperforms a financials-only baseline, underscoring the complementary contributions of acoustic and textual modalities. By decoding latent markers of uncertainty from verifiable biometric signals, our methodology provides investors and regulators a powerful tool for enhancing market interpretability and identifying hidden corporate uncertainty.
A Synergistic Framework of Nonlinear Acoustic Computing and Reinforcement Learning for Real-World Human-Robot Interaction
May 04, 2025This paper introduces a novel framework integrating nonlinear acoustic computing and reinforcement learning to enhance advanced human-robot interaction under complex noise and reverberation. Leveraging physically informed wave equations (e.g., Westervelt, KZK), the approach captures higher-order phenomena such as harmonic generation and shock formation. By embedding these models in a reinforcement learning-driven control loop, the system adaptively optimizes key parameters (e.g., absorption, beamforming) to mitigate multipath interference and non-stationary noise. Experimental evaluations-covering far-field localization, weak signal detection, and multilingual speech recognition-demonstrate that this hybrid strategy surpasses traditional linear methods and purely data-driven baselines, achieving superior noise suppression, minimal latency, and robust accuracy in demanding real-world scenarios. The proposed system demonstrates broad application prospects in AI hardware, robot, machine audition, artificial audition, and brain-machine interfaces.
CVVNet: A Cross-Vertical-View Network for Gait Recognition
May 03, 2025Gait recognition enables contact-free, long-range person identification that is robust to clothing variations and non-cooperative scenarios. While existing methods perform well in controlled indoor environments, they struggle with cross-vertical view scenarios, where surveillance angles vary significantly in elevation. Our experiments show up to 60\% accuracy degradation in low-to-high vertical view settings due to severe deformations and self-occlusions of key anatomical features. Current CNN and self-attention-based methods fail to effectively handle these challenges, due to their reliance on single-scale convolutions or simplistic attention mechanisms that lack effective multi-frequency feature integration. To tackle this challenge, we propose CVVNet (Cross-Vertical-View Network), a frequency aggregation architecture specifically designed for robust cross-vertical-view gait recognition. CVVNet employs a High-Low Frequency Extraction module (HLFE) that adopts parallel multi-scale convolution/max-pooling path and self-attention path as high- and low-frequency mixers for effective multi-frequency feature extraction from input silhouettes. We also introduce the Dynamic Gated Aggregation (DGA) mechanism to adaptively adjust the fusion ratio of high- and low-frequency features. The integration of our core Multi-Scale Attention Gated Aggregation (MSAGA) module, HLFE and DGA enables CVVNet to effectively handle distortions from view changes, significantly improving the recognition robustness across different vertical views. Experimental results show that our CVVNet achieves state-of-the-art performance, with $8.6\%$ improvement on DroneGait and $2\%$ on Gait3D compared with the best existing methods.
Human-like object concept representations emerge naturally in multimodal large language models
Jul 01, 2024



The conceptualization and categorization of natural objects in the human mind have long intrigued cognitive scientists and neuroscientists, offering crucial insights into human perception and cognition. Recently, the rapid development of Large Language Models (LLMs) has raised the attractive question of whether these models can also develop human-like object representations through exposure to vast amounts of linguistic and multimodal data. In this study, we combined behavioral and neuroimaging analysis methods to uncover how the object concept representations in LLMs correlate with those of humans. By collecting large-scale datasets of 4.7 million triplet judgments from LLM and Multimodal LLM (MLLM), we were able to derive low-dimensional embeddings that capture the underlying similarity structure of 1,854 natural objects. The resulting 66-dimensional embeddings were found to be highly stable and predictive, and exhibited semantic clustering akin to human mental representations. Interestingly, the interpretability of the dimensions underlying these embeddings suggests that LLM and MLLM have developed human-like conceptual representations of natural objects. Further analysis demonstrated strong alignment between the identified model embeddings and neural activity patterns in many functionally defined brain ROIs (e.g., EBA, PPA, RSC and FFA). This provides compelling evidence that the object representations in LLMs, while not identical to those in the human, share fundamental commonalities that reflect key schemas of human conceptual knowledge. This study advances our understanding of machine intelligence and informs the development of more human-like artificial cognitive systems.
Challenges and Contributing Factors in the Utilization of Large Language Models (LLMs)
Oct 20, 2023With the development of large language models (LLMs) like the GPT series, their widespread use across various application scenarios presents a myriad of challenges. This review initially explores the issue of domain specificity, where LLMs may struggle to provide precise answers to specialized questions within niche fields. The problem of knowledge forgetting arises as these LLMs might find it hard to balance old and new information. The knowledge repetition phenomenon reveals that sometimes LLMs might deliver overly mechanized responses, lacking depth and originality. Furthermore, knowledge illusion describes situations where LLMs might provide answers that seem insightful but are actually superficial, while knowledge toxicity focuses on harmful or biased information outputs. These challenges underscore problems in the training data and algorithmic design of LLMs. To address these issues, it's suggested to diversify training data, fine-tune models, enhance transparency and interpretability, and incorporate ethics and fairness training. Future technological trends might lean towards iterative methodologies, multimodal learning, model personalization and customization, and real-time learning and feedback mechanisms. In conclusion, future LLMs should prioritize fairness, transparency, and ethics, ensuring they uphold high moral and ethical standards when serving humanity.
Communication-efficient Byzantine-robust distributed learning with statistical guarantee
Feb 28, 2021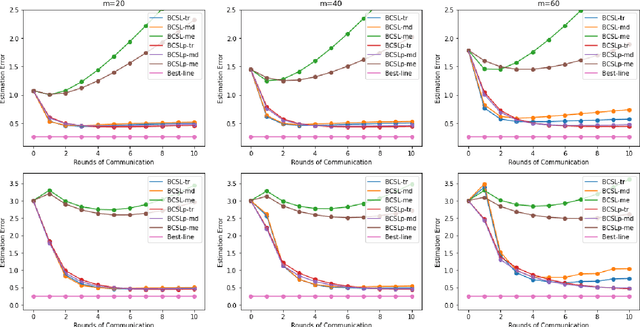
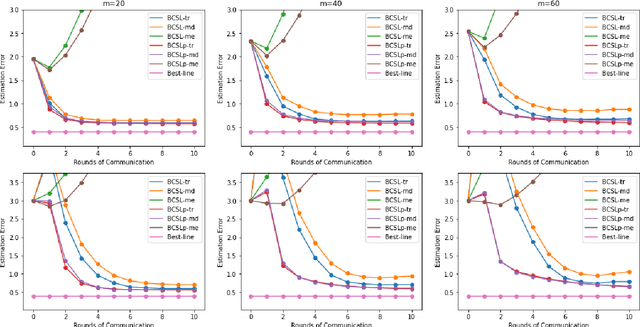
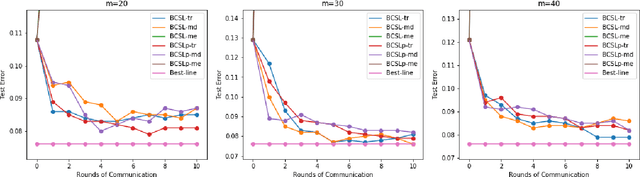
Communication efficiency and robustness are two major issues in modern distributed learning framework. This is due to the practical situations where some computing nodes may have limited communication power or may behave adversarial behaviors. To address the two issues simultaneously, this paper develops two communication-efficient and robust distributed learning algorithms for convex problems. Our motivation is based on surrogate likelihood framework and the median and trimmed mean operations. Particularly, the proposed algorithms are provably robust against Byzantine failures, and also achieve optimal statistical rates for strong convex losses and convex (non-smooth) penalties. For typical statistical models such as generalized linear models, our results show that statistical errors dominate optimization errors in finite iterations. Simulated and real data experiments are conducted to demonstrate the numerical performance of our algorithms.